import pycuda.driver as cudafrom pycuda.compiler import SourceModulecuda.init()device = cuda.Device(0)print(f"Cuda version: {".".join([str(i) for i in cuda.get_version()])}")print(f"Device:\t{device.name()}")
Cuda version: 12.8.0
Device: NVIDIA GeForce RTX 3080 Laptop GPU
in_chan_range = [1, 3, 8, 32, 128, 512]out_chan_range = [1, 4, 8, 32, 128, 512]filter_size = [1, 3, 5, 9]img_size_range = [64, 128, 256, 512, 1024]# Let's sample from the available options.n_samples =50# Generate all possible combinationscombinations = []for in_ch in in_chan_range:for out_ch in out_chan_range:for fs in filter_size:for img_size in img_size_range: n = in_ch * out_ch * img_size * img_size# Skip combinatoins that are too largeif n <1024*1024*32*32: combinations.append((in_ch, out_ch, fs, img_size))n_samples =min(n_samples, len(combinations))sampled_combinations = np.random.choice(len(combinations), size=n_samples, replace=False)test_cases = [combinations[i] for i in sampled_combinations]
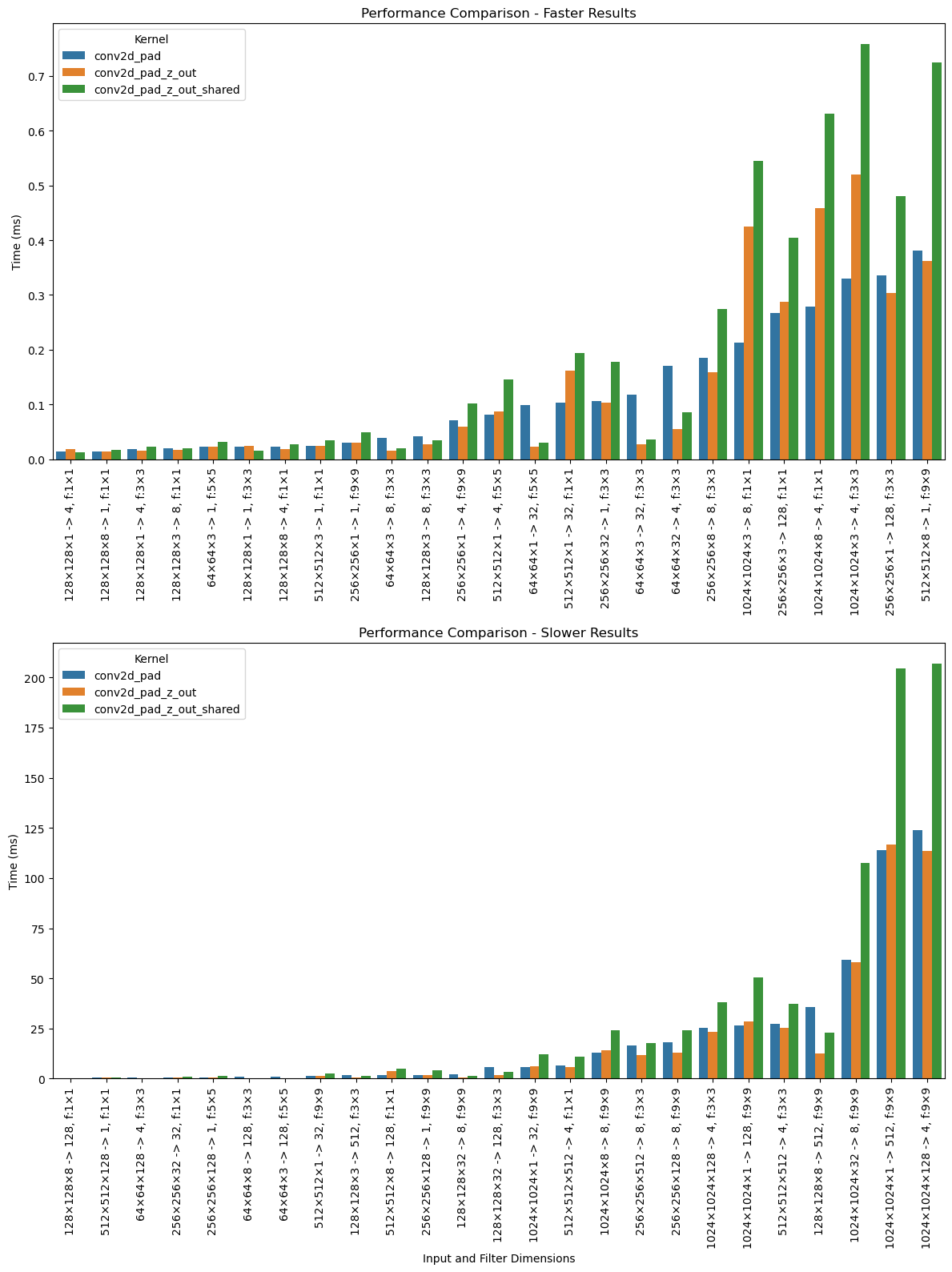
# Sort by conv2d_pad timingresults_sorted = results.sort_values(by='conv2d_pad')# Create a plot comparing the two kernelsimport matplotlib.pyplot as pltimport seaborn as sns# Create labels for x-axis that include dimensionsresults_sorted['dimensions'] = results_sorted.apply(lambda row: f"{int(row['img_size'])}×{int(row['img_size'])}×{int(row['in_ch'])} -> {int(row['out_ch'])}, f:{int(row['filter_size'])}×{int(row['filter_size'])}", axis=1)# Melt the dataframe to get it in the right format for seabornmelted_results = pd.melt( results_sorted, id_vars=['in_ch', 'out_ch', 'filter_size', 'img_size', 'dimensions'], value_vars=['conv2d_pad', 'conv2d_pad_z_out', 'conv2d_pad_z_out_shared'], var_name='kernel', value_name='time')# Split the data into two halves based on timingmidpoint =len(results_sorted) //2faster_results = melted_results[melted_results['dimensions'].isin(results_sorted['dimensions'][:midpoint])]slower_results = melted_results[melted_results['dimensions'].isin(results_sorted['dimensions'][midpoint:])]# Create a figure with two subplotsfig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 16))# Plot faster results in the first subplotsns.barplot(x='dimensions', y='time', hue='kernel', data=faster_results, ax=ax1)ax1.set_xlabel('')ax1.set_ylabel('Time (ms)')ax1.set_title('Performance Comparison - Faster Results')ax1.tick_params(axis='x', rotation=90)ax1.legend(title='Kernel')# Plot slower results in the second subplotsns.barplot(x='dimensions', y='time', hue='kernel', data=slower_results, ax=ax2)ax2.set_xlabel('Input and Filter Dimensions')ax2.set_ylabel('Time (ms)')ax2.set_title('Performance Comparison - Slower Results')ax2.tick_params(axis='x', rotation=90)ax2.legend(title='Kernel')# Adjust layoutplt.tight_layout()plt.show()# Also display the sorted results tableresults_sorted
in_ch
out_ch
filter_size
img_size
conv2d_pad_z_out_shared
conv2d_pad
conv2d_pad_z_out
dimensions
6
1
4
1
128
0.013312
0.014677
0.018432
128×128×1 -> 4, f:1×1
37
8
1
1
128
0.017408
0.014677
0.013995
128×128×8 -> 1, f:1×1
23
1
4
3
128
0.022560
0.017749
0.015019
128×128×1 -> 4, f:3×3
20
3
8
1
128
0.019456
0.019797
0.016384
128×128×3 -> 8, f:1×1
35
3
1
5
64
0.032085
0.022187
0.022528
64×64×3 -> 1, f:5×5
11
1
1
3
128
0.015701
0.022187
0.024576
128×128×1 -> 1, f:3×3
36
8
4
1
128
0.026624
0.023211
0.018432
128×128×8 -> 4, f:1×1
16
3
1
1
512
0.034133
0.024917
0.024917
512×512×3 -> 1, f:1×1
3
1
1
9
256
0.048811
0.030720
0.030379
256×256×1 -> 1, f:9×9
29
3
8
3
64
0.019797
0.038571
0.016043
64×64×3 -> 8, f:3×3
28
3
8
3
128
0.034475
0.041984
0.026891
128×128×3 -> 8, f:3×3
27
1
4
9
256
0.102400
0.070997
0.060075
256×256×1 -> 4, f:9×9
30
1
4
5
512
0.145067
0.081291
0.087381
512×512×1 -> 4, f:5×5
24
1
32
5
64
0.030379
0.098645
0.022187
64×64×1 -> 32, f:5×5
43
1
32
1
512
0.193536
0.103765
0.162133
512×512×1 -> 32, f:1×1
44
32
1
3
256
0.177493
0.105813
0.102741
256×256×32 -> 1, f:3×3
26
3
32
3
64
0.035861
0.117419
0.026624
64×64×3 -> 32, f:3×3
19
32
4
3
64
0.086016
0.169984
0.055637
64×64×32 -> 4, f:3×3
48
8
8
3
256
0.274411
0.184661
0.159061
256×256×8 -> 8, f:3×3
22
3
8
1
1024
0.545109
0.212992
0.424960
1024×1024×3 -> 8, f:1×1
8
3
128
1
256
0.403819
0.267605
0.287712
256×256×3 -> 128, f:1×1
45
8
4
1
1024
0.630827
0.278187
0.458411
1024×1024×8 -> 4, f:1×1
31
3
4
3
1024
0.758027
0.330411
0.520192
1024×1024×3 -> 4, f:3×3
18
1
128
3
256
0.480256
0.335189
0.303787
256×256×1 -> 128, f:3×3
17
8
1
9
512
0.724992
0.380587
0.361813
512×512×8 -> 1, f:9×9
39
8
128
1
128
0.270379
0.387413
0.155989
128×128×8 -> 128, f:1×1
25
128
1
1
512
0.657067
0.400043
0.393557
512×512×128 -> 1, f:1×1
14
128
4
3
64
0.310613
0.631808
0.172032
64×64×128 -> 4, f:3×3
32
32
32
1
256
1.176277
0.664235
0.752640
256×256×32 -> 32, f:1×1
33
128
1
5
256
1.505963
0.763904
0.733867
256×256×128 -> 1, f:5×5
2
8
128
3
64
0.202411
1.090560
0.121173
64×64×8 -> 128, f:3×3
49
3
128
5
64
0.228352
1.109632
0.112299
64×64×3 -> 128, f:5×5
13
1
32
9
512
2.565461
1.423701
1.346496
512×512×1 -> 32, f:9×9
42
3
512
3
128
1.388171
1.845259
0.712021
128×128×3 -> 512, f:3×3
21
8
128
1
512
4.980736
1.896128
3.599317
512×512×8 -> 128, f:1×1
9
128
1
9
256
4.014080
1.963691
1.923755
256×256×128 -> 1, f:9×9
46
32
8
9
128
1.408363
1.988608
0.731477
128×128×32 -> 8, f:9×9
0
32
128
3
128
3.384661
5.587627
1.667072
128×128×32 -> 128, f:3×3
40
1
32
9
1024
12.256256
5.811200
6.014293
1024×1024×1 -> 32, f:9×9
47
512
4
1
512
11.096747
6.729387
5.955925
512×512×512 -> 4, f:1×1
4
8
8
9
1024
24.125451
12.846773
14.283093
1024×1024×8 -> 8, f:9×9
41
512
8
3
256
17.939190
16.718848
11.764704
256×256×512 -> 8, f:3×3
38
128
8
9
256
24.203318
18.254550
12.945440
256×256×128 -> 8, f:9×9
5
128
4
3
1024
37.974016
25.287701
23.289515
1024×1024×128 -> 4, f:3×3
7
1
128
9
1024
50.371583
26.570752
28.357973
1024×1024×1 -> 128, f:9×9
34
512
4
3
512
37.451136
27.270486
25.335520
512×512×512 -> 4, f:3×3
1
8
512
9
128
23.107925
35.587467
12.653866
128×128×8 -> 512, f:9×9
12
32
8
9
1024
107.734355
59.062336
57.880950
1024×1024×32 -> 8, f:9×9
10
1
512
9
1024
204.436142
113.762347
116.663638
1024×1024×1 -> 512, f:9×9
15
128
4
9
1024
206.882517
124.058678
113.531560
1024×1024×128 -> 4, f:9×9
For some reason, the version with shared memory is actually slower. Not entirely sure why, because it looks correct